def fetch_author_papers(author_id):
"""Fetch papers from Semantic Scholar API"""
base_url = "https://api.semanticscholar.org/graph/v1"
fields = "paperId,title,authors,year,venue,publicationDate,externalIds,openAccessPdf,url"
url = f"{base_url}/author/{author_id}/papers"
params = {'fields': fields, 'limit': 1000}
try:
response = requests.get(url, params=params)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"Error fetching data from Semantic Scholar: {e}")
return None
def create_yaml_entry_from_ss_paper(paper):
"""Convert Semantic Scholar paper to YAML entry format"""
paper_id = paper.get('paperId')
title = paper.get('title', 'Untitled')
year = paper.get('year')
venue = paper.get('venue', '')
# Process authors
authors = []
for author in paper.get('authors', []):
author_name = author.get('name', '')
if 'Dimmery' in author_name:
authors.append("me")
else:
authors.append(author_name)
entry = {
'title': title,
'authors': authors,
'year': year,
'venue': venue if venue else None,
'visible': False, # Default to not visible
'ssid': paper_id,
}
# Add external links if available
external_ids = paper.get('externalIds', {})
if external_ids.get('DOI'):
entry['published_url'] = f"https://doi.org/{external_ids['DOI']}"
if external_ids.get('ArXiv'):
entry['preprint'] = f"https://arxiv.org/abs/{external_ids['ArXiv']}"
# Add open access PDF if available
open_access = paper.get('openAccessPdf')
if open_access and open_access.get('url'):
entry['pdf_url'] = open_access['url']
return entryI’ve made a few changes and updates to this website. None of them are particularly earth-shattering, but I think building one’s own tools—rather than accepting the constraints of platforms—is worth the effort.
Here’s what I’ve been working on:
- Semantic Scholar integration for updating publication records
- Listmonk tools for sharing blog posts as a newsletter
- Improvements to the design and performance, particularly around fonts
I think these changes are consistent with the philosophy I introduced in the last post. I’ll introduce each briefly and discuss how they work—perhaps they’ll be useful to others building their own corners of the web.
Semantic Scholar integration
I’ve had a consistent desire to avoid tedious data entry in updating my website. This was part of my intention when I moved it to Quarto in the first place: Quarto gives great opportunity to programmatically generate a static website. I can easily mix in rich documents that combine code (R and Python in particular) and easily formatted Markdown text. This is all great. It let me hack together a nice way to display my publications in a consistent format based on data stored in a hand-curated YAML file. The next step was to automate the process of updating the publication records. I used the Semantic Scholar API to fetch the latest information about my publications and then used Quarto’s templating capabilities to generate the updated publication list.
Most of the work of this system is in two functions which, because I vibe-coded it, I’ve never really even looked at.
See the code
Critically, this is all pretty trivial, but it’s also boring, so I’m glad I didn’t need to think particularly hard about it. It also means I didn’t need to personally dig through the Semantic Scholar API documentation. The code quality is not great, but neither was my own code before!
So now when I build the site, it automatically updates the YAML with my latest papers. I can just browse through them and flip the visible flag to show them once I’m satisfied they’re right.
Listmonk tools
The second main improvement I made was to add an email distribution list to my website’s blog. This was pretty easy because of the great open source email distribution software, Listmonk, and the super easy deployment option at Pikapods. The system I’ve come up with is basically the following:
- Write a blog post in a Quarto document.
- Push it to a branch if I want to have sensitivity readers.
- Once I’m satisfied, push it to main, which automatically triggers a Quarto build of the website and makes the blog post “live” on the website (and RSS feed)
- Manually trigger a Github Actions workflow to schedule a Listmonk email campaign.
It’s this last part that I think is particularly cool. Basically the way it works is I vibecoded an over-engineered system that pulls the necessary metadata from a given blog post (in the .qmd file), renders the post to an HTML version, extracts the HTML from that, and sends all of this through Listmonk’s API to schedule an email campaign with nicely formatted HTML content. I’m not going to embed all of the scripts for this here, but you can take a look at them in my website’s Github: scripts/.
To actually trigger this monstrosity, I used a nice feature that Github Actions provides: workflow_dispatch event triggers. Basically, what this means is that you can configure a Github Action to trigger manually through the Github UI. It looks something like this:
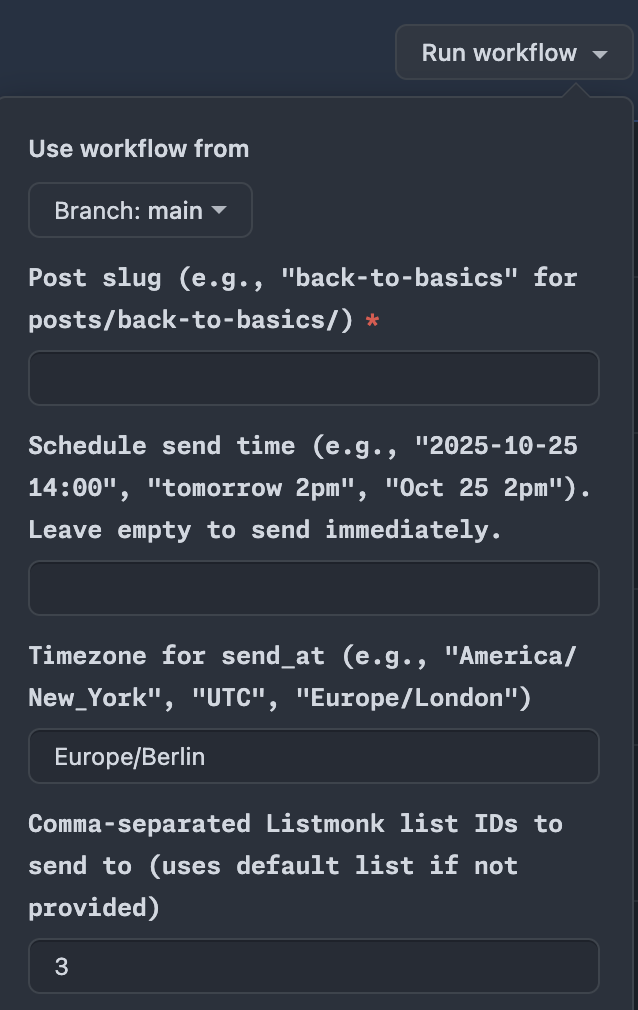
So basically all I need to do is tell the workflow what post to schedule (the post_slug part), when to schedule it (the send_at). There are also a few optional things I can plug in, such as which list to send to (Listmonk lets me manage multiple lists easily), or I can send test emails.
This is a solution I’m mostly happy with. I think there’s still a bit of tweaking about some of the practicalities. I think there are two things I’m trying to figure out:
- Whether I should maintain separate lists for different categories of post. It wouldn’t be hard to maintain category-specific lists so that people could easily opt-out of posts about (e.g.) how I built things on my website.
- How exactly to manage the sending of emails. When I sent out the last email, it only sent to like two-thirds of my subscribers because my email provider is Protonmail setup with a custom
blog@email address for sending/receiving. Unfortunately, there were some rate limits that I didn’t adequately respect the first time.
I’m overall pretty pleased with this system. You’re welcome to subscribe here!
Improvements in design and performance
Within me are two wolves: Sometimes I miss the days of HTML-only websites. Other days, I long for the ability to have nicely reactive and responsive design elements that require richer web frameworks. On some personal projects over the last few months, I’ve learned a bit more about modern webdev tools. One thing I’m particularly taken by is the way that modern webdev tools like Vite manage javascript dependencies.
In short, the problem with a lot of these big web frameworks is that they’re really big (duh)! They have a lot of stuff that you never use in a small personal website like mine, but they still get bundled into the library that is sent down to the website viewer. We don’t need to do that: we can be smarter. That’s basically what tools like Vite do. They only bundle together the parts of code that are necessary for the particular site being built. They also can help with lazy loading (so they’re only loaded when needed).
That’s all a bit of a tangent, but it’s gotten me thinking about why I actually need to load so many Javascript libraries. Quarto ultimately doesn’t seem to be particularly optimized on this front. This is kind of the tradeoff you get: sure, it’s easy to throw something together with Quarto that has a lot of the bells and whistles a data scientist craves, but that doesn’t mean it’s going to be super efficient. There’s a really nice post by Emil Hvitfeldt discussing performance considerations in Quarto.
Purge unused resources
I in-lined many icons to embedded svgs, but, alas, Quarto still loads the bootstrap-icons.css that it does not, as far as I can tell, use anywhere. The solution to this was described in a discussion about Quarto performance by Charles Nepote. Quarto makes it possible to add a post-rendering step to builds which purges unused CSS and minifies JS and CSS (see here). I found that this did a really nice job of reducing the size of resources that needed to be fetched from my site. This helped, and brought the critical path latency down a good bit. After reducing as much of these resources as I could, the critical path is currently loading quarto.js. I think this is probably about as good as it gets1. Or, at least, as good as it gets without me just basically giving up on letting Quarto manage this at all.
Fonts
Here’s some fun Drew-lore: I’m weirdly into fonts. In the summer before my PhD I read like 3 books about fonts that I marked up more than almost anything else I’ve read.
My font choices
Long story short, I’ve currently landed on the following font styling that I intend to use pretty generally across the web, in documents and on presentations2:
- Headers in URW Classico. This is a font based largely on Optima.
- Body text in Domitian. This is a font based largely on the venerable Palatino.
- Code in
Monaspace Argon. This is part of the suite of fonts developed by Github Next. It’s also the primary font I use locally in my IDE. It’s a Humanist Sans font (I have tried to use Serifed fonts for coding, but it just looks utterly wrong to me). - Math in \(\text{Neo-Euler}\). When I use math, I want it to stand out as distinct from the surrounding text. I think Neo-Euler does a good job of walking the line between being a little weird while remaining easy to read.
Why humanist fonts matter
These fonts are all strongly humanist in orientation and free3. Despite a brief flirtation with Futura, I have come around to the importance of fonts which embrace more complexity than such geometric renderings. Ultimately, I think the omni-presence of sans-serifed fonts on the web is a reflection of its inhumanity. Good text should have character in style as well as in substance. I think the ubiquity of sans-serifs on the web is indicative of the fact that it isn’t really a place for reading. The medium corresponding to sans-serifs is the microblog, not the book. Bringing back subtle variations in stroke width, text-oriented serifs and other organic qualities of humanist fonts is a (very) small step towards reclaiming the web.
Loading fonts performantly
To use these custom fonts on the web without screwing with performance too much, I used the solution detailed here to make sure fonts can be preloaded and also that they aren’t part of the critical path for rendering. When you load a page here, you might see a replacement background font for a split-second before the font faces are loaded into the CSS.
Remaining concerns
I’m happy with a lot of what has come together. There are a few issues that I think can be improved. I’m considering whether it might make sense to switch to a hybrid system which would use Quarto to build minimal HTML or Markdown documents which are then knit together using a modern web development framework like Astro. This would allow much more granular control over the website and how it loads resources, but could still get the benefits of Quarto where it is most useful (for pre-rendering rich documents full of Python and R code). This is probably a bigger project than I imagine it to be, so I don’t intend to commit to it soon4.
I’m also considering whether it would make more sense to switch to a different hosting solution. I’m not particularly pleased with the quality of Netlify’s CDN, which seems to be a bit slow in Europe (I suspect they just have fewer edge locations)5. I’m considering whether it might make sense to switch to a system which is self-hosted in a VPS like DigitalOcean/Hetzner (possibly with a tool like Coolify to manage deployment) and then add a CDN like Cloudflare over the top. The benefit to this is that it would combine control (from the self-hosted VPS) with the performance benefits of a reliable CDN through Cloudflare, but it would remain quite cheap (albeit not free).
Tending the garden
There’s something satisfying about all of this tinkering that I find hard to articulate. It’s not that any individual piece is particularly impressive or novel. Rather, it’s the act of construction itself—of shaping raw materials into something that reflects intention and care. McLuhan observed that we shape our tools, and thereafter our tools shape us. The platforms we’ve ceded our digital lives to have shaped us into consumers of content, optimized for something outside of our control. Building my own corner of the web is a small act of resistance against this.
I don’t think everyone needs to hand-roll their entire tech-stack or obsess over font choices (I will tell you fonts are a huge net-negative on my measurable productivity). But I do think there’s value in the process of understanding and improving the systems we inhabit, even if only to understand what we’ve given up by outsourcing them. The web was supposed to be a place where anyone could plant a flag and build something. Somewhere along the way, we traded that for the convenience of renting space in someone else’s domain.
These updates—the automation, the newsletters, the performance tweaks, the typography—are all just ways of making this place more my own. The work is never finished. There’s always another edge to smooth, another inefficiency to address. But that’s the point, isn’t it?
Footnotes
It seems like there are also some other problems, as Firefox and Chrome both intermittently show several seconds to establish a SSL connection to the website (i.e. before any resources are actually loaded). Unclear what’s going on with this…↩︎
The ease of writing Markdown documents which are rendered into reveal.js HTML presentations is really nice, and yet another way that I’m aiming at convergence between these media. I ask myself whether I should also move away from directly writing LaTeX, too. Ensuring visual consistency by using literally identical styling directives is very appealing.↩︎
We’re Hermann Zapf fans over here if you couldn’t tell.↩︎
Truly famous last words.↩︎
Making a connection via HTTPS occasionally takes 3s or more, which is just absurd and is by far the slowest part of page-load, although it is also intermittent which makes me suspect something with CDNs.↩︎
Reuse
Citation
BibTeX citation:
@online{dimmery2025,
author = {Dimmery, Drew},
title = {Website {Refresh}},
date = {2025-11-19},
url = {https://ddimmery.com/posts/website-refresh/},
langid = {en}
}
For attribution, please cite this work as:
Dimmery, Drew. 2025. “Website Refresh.” November 19. https://ddimmery.com/posts/website-refresh/.